
Blografia.net
Last update: January 27, 2026 10:03 AM
January 24, 2026
Gwolf
Finally some light for those who care about Debian on the Raspberry Pi
Finally, some light at the end of the tunnel!
As I have said in this blog and elsewhere, after putting quite a bit of work into generating the Debian Raspberry Pi images between late 2018 and 2023, I had to recognize I don’t have the time and energy to properly care for it.
I even registered a GSoC project for it. I mentored Kurva Prashanth, who did good work on the vmdb2 scripts we use for the image generation — but in the end, was unable to push them to be built in Debian infrastructure. Maybe a different approach was needed! While I adopted the images as they were conceived by Michael Stapelberg, sometimes it’s easier to start from scratch and build a fresh approach.
So, I’m not yet pointing at a stable, proven release, but to a good
promise. And I hope I’m not being pushy by making this public: in the
#debian-raspberrypi channel, waldi has shared the images he has created
with the Debian Cloud Team’s infrastructure.
So, right now, the images built so far support Raspberry Pi families 4 and 5 (notably, not the 500 computer I have, due to a missing Device Tree, but I’ll try to help figure that bit out… Anyway, p400/500/500+ systems are not that usual). Work is underway to get the 3B+ to boot (some hackery is needed, as it only understands MBR partition schemes, so creating a hybrid image seems to be needed).

Sadly, I don’t think the effort will be extended to cover older, 32-bit-only systems (RPi 0, 1 and 2).
Anyway, as this effort stabilizes, I will phase out my (stale!) work on
raspi.debian.net, and will redirect it to point at the new images.
Comments
Andrea Pappacoda tachi@d.o 2026-01-26 17:39:14 GMT+1
Are there any particular caveats compared to using the regular Raspberry Pi OS?
Are they documented anywhere?
Gunnar Wolf gwolf.blog@gwolf.org 2026-01-26 11:02:29 GMT-6
Well, the Raspberry Pi OS includes quite a bit of software that’s not packaged in Debian for various reasons — some of it because it’s non-free demo-ware, some of it because it’s RPiOS-specific configuration, some of it… I don’t care, I like running Debian wherever possible 😉
Andrea Pappacoda tachi@d.o 2026-01-26 18:20:24 GMT+1
Thanks for the reply! Yeah, sorry, I should’ve been more specific. I also just care about the Debian part. But: are there any hardware issues or unsupported stuff, like booting from an SSD (which I’m currently doing)?
Gunnar Wolf gwolf.blog@gwolf.org 2026-01-26 12:16:29 GMT-6
That’s… beyond my knowledge 😉 Although I can tell you that:
-
Raspberry Pi OS has hardware support as soon as their new boards hit the market. The ability to even boot a board can take over a year for the mainline Linux kernel (at least, it has, both in the cases of the 4 and the 5 families).
-
Also, sometimes some bits of hardware are not discovered by the Linux kernels even if the general family boots because they are not declared in the right place of the Device Tree (i.e. the wireless network interface in the 02W is in a different address than in the 3B+, or the 500 does not fully boot while the 5B now does). Usually it is a matter of “just” declaring stuff in the right place, but it’s not a skill many of us have.
-
Also, many RPi “hats” ship with their own Device Tree overlays, and they cannot always be loaded on top of mainline kernels.
January 14, 2026
Gwolf
The Innovation Engine • Government-funded Academic Research
This post is an unpublished review for The Innovation Engine • Government-funded Academic Research
David Patterson does not need an introduction. Being the brain behind many of the inventions that shaped the computing industry (repeatedly) over the past 40 years, when he put forward an opinion article in Communications of the ACM targeting the current day political waves in the USA, I could not avoid choosing it to write this review.
Patterson worked for a a public university (University of California at Berkeley) between 1976 and 2016, and in this article he argues how government-funded academic research (GoFAR) allows for faster, more effective and freer development than private sector-funded research would, putting his own career milestones as an example of how public money that went to his research has easily been amplified by a factor of 10,000:1 for the country’s economy, and 1,000:1 particularly for the government.
Patterson illustrates this quoting five of the “home-run” research projects he started and pursued with government funding, eventually spinning them off as successful startups:
- RISC (Reduced Instruction Set Computing): Microprocessor architecture that reduces the complexity and power consumption of CPUs, yielding much smaller and more efficient processors.
- RAID (Redundant Array of Inexpensive Disks): Patterson experimented with a way to present a series of independent hard drive units as if they were a single, larger one, leading to increases in capacity and reliability beyond what the industry could provide in single drives, for a fraction of the price.
- NOW (Network Of Workstations): Introduced what we now know as computer clusters (in contrast of large-scale massively multiprocessed cache-coherent systems known as “supercomputers”), which nowadays power over 80% of the Top500 supercomputer list and are the computer platform of choice of practically all data centers.
- RAD Lab (Reliable Adaptive Distributed Systems Lab): Pursued the technology for data centers to be self-healing and self-managing, testing and pushing early cloud-scalability limits
- ParLab (Parallel Computing Lab): Given the development of massively parallel processing inside even simple microprocessors, this lab explores how to improve designs of parallel software and hardware, presenting the ground works that proved that inherently parallel GPUs were better than CPUs at machine learning tasks. It also developed the RISC-V open instruction set architecture.
Patterson identifies principles for the projects he has led, that are specially compatible with the ways research works at universitary systems: Multidisciplinary teams, demonstrative usable artifacts, seven- to ten-year impact horizons, five-year sunset clauses (to create urgency and to lower opportunity costs), physical proximity of collaborators, and leadership followed on team success rather than individual recognition.
While it could be argued that it’s easy to point at Patterson’s work as a success example while he is by far not the average academic, the points he makes on how GoFAR research has been fundamental for the advance of science and technology, but also of biology, medicine, and several other fields are very clear.
January 12, 2026
Gwolf
Python Workout 2nd edition
This post is an unpublished review for Python Workout 2nd edition
Note: While I often post the reviews I write for Computing Reviews, this is a shorter review requested to me by Manning. They kindly invited me several months ago to be a reviewer for Python Workout, 2nd edition; after giving them my opinions, I am happy to widely recommend this book to interested readers.
Python is relatively an easy programming language to learn, allowing you to start coding pretty quickly. However, there’s a significant gap between being able to “throw code” in Python and truly mastering the language. To write efficient, maintainable code that’s easy for others to understand, practice is essential. And that’s often where many of us get stuck. This book begins by stating that it “is not designed to teach you Python (…) but rather to improve your understanding of Python and how to use it to solve problems.”
The author’s structure and writing style are very didactic. Each chapter addresses a different aspect of the language: from the simplest (numbers, strings, lists) to the most challenging for beginners (iterators and generators), Lerner presents several problems for us to solve as examples, emphasizing the less obvious details of each aspect.
I was invited as a reviewer in the preprint version of the book. I am now very pleased to recommend it to all interested readers. The author presents a pleasant and easy-to-read text, with a wealth of content that I am sure will improve the Python skills of all its readers.
January 10, 2026
Victor Martínez
Antropología y sociología
Me dice FB que hace tres años andaba jugando con una imagen de una serie nueva, que dicho sea de paso me gusto bastante «Wednesday». Del cual hicieron el siguiente meme.

Por supuesto la imagen la compartieron en un foro de antropólogos… y bueno hice una edición de la misma.

Porque al menos cuando yo estudié era un poco más así, por ahí me comentaron que la primera imagen era más correcta para mi caracter que la segunda y me supongo que es cierto, pero el meme y la idea por la que hice mi edición fue por la disciplina no por el como soy yo.
En fin que no lo puse por acá en su momento y aprovechando que el chismoso de FB me lo recordó mejor lo pongo por acá.
January 07, 2026
Gwolf
Artificial Intelligence • Play or break the deck
This post is an unpublished review for Artificial Intelligence • Play or break the deck
As a little disclaimer, I usually review books or articles written in English, and although I will offer this review to Computing Reviews as usual, it is likely it will not be published. The title of this book in Spanish is Inteligencia artificial: jugar o romper la baraja.
I was pointed at this book, published last October by Margarita Padilla García, a well known Free Software activist from Spain who has long worked on analyzing (and shaping) aspects of socio-technological change. As other books published by Traficantes de sueños, this book is published as Open Access, under a CC BY-NC license, and can be downloaded in full. I started casually looking at this book, with too long a backlog of material to read, but soon realized I could just not put it down: it completely captured me.
This book presents several aspects of Artificial Intelligence (AI), written for a general, non-technical audience. Many books with a similar target have been published, but this one is quite unique; first of all, it is written in a personal, non-formal tone. Contrary to what’s usual in my reading, the author made the explicit decision not to fill the book with references to her sources (“because searching on Internet, it’s very easy to find things”), making the book easier to read linearly — a decision I somewhat regret, but recognize helps develop the author’s style.
The book has seven sections, dealing with different aspects of AI. They are the “Visions” (historical framing of the development of AI); “Spectacular” (why do we feel AI to be so disrupting, digging particularly into game engines and search space); “Strategies”, explaining how multilayer neural networks work and linking the various branches of historic AI together, arriving at Natural Language Processing; “On the inside”, tackling technical details such as algorithms, the importance of training data, bias, discrimination; “On the outside”, presenting several example AI implementations with socio-ethical implications; “Philosophy”, presenting the works of Marx, Heidegger and Simondon in their relation with AI, work, justice, ownership; and “Doing”, presenting aspects of social activism in relation to AI. Each part ends with yet another personal note: Margarita Padilla includes a letter to one of her friends related to said part.
Totalling 272 pages (A5, or roughly half-letter, format), this is a rather small book. I read it probably over a week. So, while this book does not provide lots of new information to me, the way how it was written, made it a very pleasing experience, and it will surely influence the way I understand or explain several concepts in this domain.
December 31, 2025
Diario de un Mexicano en Japon
¡Feliz 2026!

あけおめことよろです!
Lo anterior es ya una forma que ya se puede considerar arcaica de decir “¡feliz año nuevo!” en japonés. Estuvo de moda hace muchos años, por lo que creo que ningún joven ahora la use… pero uno nunca sabe.
El caso es que ya ha comenzado el 2026, y con él, una nueva oportunidad de darle un mejor rumbo a nuestra efímera existencia en este mundo.
Este año es el del CABALLO. Lo pongo en mayúsculas porque es el año del animal en el que nací, lo que me convierte a mí y a todos los que cumplan años en múltiplos de 12, en 年男 (toshi otoko) o 年女 (toshi onna), según sea el caso. Ignoro totalmente cómo se maneje para quienes no se identifiquen con uno de esos dos géneros, así que en vez de escribir una falacia, mejor acepto que no sé… Regresando al punto, este año cumpliré 48 primaveras… y ya veo así bien “cerquitas” el quinto piso… ¡Chaaaaaaangos! Sí que ha pasado el tiempo.
Deseo que el 2026 sea el mejor año que hayan tenido en sus vidas. Aquí andamos todavía.
Reciban un abrazo desde las tierras de Saitama, en Japón
The post ¡Feliz 2026! first appeared on ¡Un mexicano en Japón!.December 30, 2025
Diario de un Mexicano en Japon
El 2025 en un kanji
Ligas a años anteriores:
- El 2024 en un kanji
- El 2023 en un kanji
- El 2022 en un kanji
- El 2021 en un kanji
- El 2020 en un kanji
- El 2019 en un kanji
- El 2018 en un kanji
- El 2017 en un kanji
- El 2016 en un kanji
- El 2015 en un kanji
- El 2014 en un kanji
- El 2013 en un kanji
- El 2012 en un kanji
- El 2011 en un kanji
- El 2010 en un kanji
- El 2009 en un kanji
- El 2008 en un kanji
- El 2007 en un kanji
¡Hola blog!
(Tuve que hacer una pausa para ir a regañar a los niños porque se estaban peleando… a las 10 PM…)
Vamos recapitulando el año que termina.
Primero que nada, sí escribí más que el año anterior. Quizá no es tanto como hubiera querido, pero se cumplió el propósito que hice a prinicipios de 2025.
Segundo, y entrando de lleno en el tema de este escrito: el kanji de este año prácticamente lo tenía decidido desde justamente finales de 2024. Cuando tuve que decidir qué kanji escogería para ese año, inmediatamente pensé en 2 candidatos, pero me decidí por 「築」 porque envolvía más adecuadamente lo acaecido justo en los últimos meses de 2024. El segundo candidato sería entonces el elegido para ser el kanji de 2025, aunque ahora en diciembre dudé un poco debido a un viaje de trabajo que tuve a Ciudad de México, aventura que contaré en otra ocasión. Sin embargo, a final me decidí por el que ya tenía elegido porque en definitiva es un parteaguas en mi jornada en el país del sol naciente.
Sin más preámbulos, mi kanji del 2025 es:

Significa tal cual “casa”. Si el año pasado el kanji fue para reconocer todo lo que quedó consolidado para el futuro, el de este año indudablemente tenía que ser el kanji de “casa” porque, después de casi 23 años de vivir de este lado del charco, decidí dar un gran paso en mi vida y comprar casa en Japón. O bueno, sacar un crédito para pagar la casa y tener que pagarlo hasta que tenga 79 años. Pero de momento, olvidémonos de los detalles que no son felices y concentrémonos en los que sí lo son.
Aunque todavía no termino de recapitular el 2023, sinceramente nunca pensé que estaria escribiendo que había comprado una casa 2 años después siendo que mi situación al final de ese año no era para nada buena. Obviamente voy a entrar en más detalles en la última parte de esa serie, pero les puedo adelantar lo siguiente:
- A finales de octubre de 2023 hubo despidos masivos en la empresa en la que laboraba en ese entonces
- Estuve enviando currículums a todo lo que se moviera porque sin trabajo nos íbamos a quedar en la calle en cuestión de medio año
- Me batearon de muchísimas empresas
- Terminé en una empresa internacional, en al menos una mejor posición en la que estaba antes
El último de los puntos anteriores fue lo que nos (contando a mi esposa porque ella se aventó una buena parte de los trámites y de entender todo lo que había que hacer) motivó a tomar la decisión de adquirir vivienda propia… en caso de que una cumpliera las condiciones que buscábamos y que se adecuara a nuestro presupuesto. Y justamente en octubre de 2024 mi esposa, que para ese entonces ya tenía como pasatiempo estar buscando casas (no es broma), se percató que una vivienda que le gustaba y que había estado a la venta durante casi un año había bajado de precio a uno que sí se acomodaba, así que, prácticamente de un día para otro, comenzamos la odisea de la compra de la casa.
Un acontecimiento de tal magnitud definitivamente merece un escrito exclusivo, así que omitiré, por el momento, muchos detalles e información que quizá pudiera serle útil a alguien que se quiera aventar a comprar casa en Japón.
La conclusión, después de tooooooodo el show y el mar de trámites, que por cierto todavía no terminan, logré sacar un préstamo de un banco, adquirir un seguro para que la deuda se cancele en caso de que yo muera o no pueda trabajar por alguna enfermedad terminal y comprar el inmueble desde el que estoy escribiendo este escrito.
Hay muchos, muchísimos detalles que comentar respecto a la adquisición de una casa en Japón, pero el punto que más quiero enfatizar en este momento es el hecho de que las casas en este país PIERDEN VALOR con el paso de los años, al grado de que en 15 o 20 años, esta vivienda va a valer prácticamente 0 yenes; lo que TIENE LA POSIBILIDAD de tener plusvalía es el terreno, pero no es 100% seguro. En el peor de los casos, el valor del terreno quedaría en lo mismo en lo que lo adquirimos.
Se preguntarán entonces para qué comprar una casa si no es un patrimonio seguro con lo sería en México (y en muchos otros países). Y la respuesta es simple: para tener patrimonio, aunque no le ganemos nada. Ya siendo más prácticos y realistas:
- Continuar rentando siempre es opción, pero a final de cuentas terminas con nada en las manos
- Cuando tienes niños, vivir en departamentos siempre genera más estrés de lo normal porque tienes que estar cuidando de que no hagan ruido después de ciertas horas, y algunas veces es imposible, por lo que terminas ganándote quejas de los vecinos
- Creo que para un niño es importante tener un lugar al qué llamar “casa”. Cierto: puede ser uno rentado, y no le quita para nada mérito el que lo sea, pero al menos mi percepción siempre fue la de tener un lugar fijo al que uno pueda regresar en el futuro. Es difícil explicarlo, pero bien que mal, la casa en la que crecí era propia, y de alguna forma siempre me sentía seguro ahí
- Ya era hora de decidir quedarme en Japón o regresar a México. Sí, ya sé, han sido casi 23 años, pero aunque regresar a mi rancho todavía es opción en el futuro, tenía que decidir que estaría en Japón por al menos unos 10 o 15 años más, en lo que los niños crecen y se desarrollan. Tuve muchas dudas en años anteriores porque siempre estaba a la expectativa de que en cualquier momento pudiera presentarse algo en México que me convenciera a volver, pero eso no le daba nada de seguridad a mi familia, no porque me fuera a dejar solo, sino porque no podíamos trazar un plan de desarrollo a largo plazo. En corto: me manché con el tiempo que me tomó llegar a este punto
Soy firme creyente de que no hay casualidades, y de que nunca entendemos por qué suceden las cosas hasta que volteamos a ver todo lo que nos llevó a ellas. Para mí, este fue el momento perfecto para dar el “salto de fe” y echarme la deuda de la casa encima, pero lo hago después de haber estado en el fondo de un pozo por la depresión, después de pasar días, semanas y meses con un futuro incierto por mala administración del jefe de la empresa en la que trabajé hasta principios de 2024, y después de haber casi reconstruido del todo mis mecanismos de autodefensa y autoestima. Por ello, aunque nunca he sido fan de tener algo físico para demostrar que hice algo, la casa representa un pilar, un momento grande de mi vida en el que me volví a edificar después de tocar fondo y estar completamente destrozado física y emocionalmente. Y es precisamente por eso que mi kanji de 2025 es 「家」.
El kanji de 2025 en Japón
Japón también tuvo grandes momentos históricos este año. Quizá el más relevante fue el de es la primera vez que una mujer se convierte en primer ministro del país: Sanae Takaichi; el costo de los bienes y servicios se fue a las alturas, y ahora pagamos por el arroz más del doble de lo que pagábamos hace apenas 3 o 4 años, y ni se diga de los aumentos en los impuestos… Y para los extranjeros que residimos aquí, se viene un endurecimiento de los requisitos para vivir, así como de un aumento, por demás exagerado, de las cuotas para la renovación del estatus de residencia… pero eso ya lo contaré en otra ocasión.
El caso es que había muchos candidatos muy buenos para coronarse como el kanji del año en el país, pero para sorpresa de muchos, el escogido fue 「熊」 (kuma), que literalmente significa “oso”, principalmente por el aumento de ataques de esos animales a humanos. Pero no crean: hay quienes dicen que es una “tapadera” del gobierno para evitar dar una mala impresión, y que los kanji que realmente reflejan la condición actual del país bien pudieran ser 「税」 (“sei”, impuesto), 「高」(“taka”, “kou”, literalmente “alto”, por la primer ministro Sanae Takaichi 「高市早苗」… y la realidad es que esos kanji están entre los primeros 20 lugares de los votados este año. Con todo, y siendo que no me gusta la política en general, dejo esas confabulaciones, rumores y demás, a los debidos blogs, videoblogs, tiktoks y similares “expertos” (noten las comillas) en el tema.
Qué esperar en el 2026
Hablo concretamente del blog. No quiero prometer algo que no pueda cumplir, pero sí quiero prometer seguir con la tendencia de escribir más seguido.
En un comentario recibido hace ya tiempo me decían que este blog debería haber “evolucionado” a un videoblog. La verdad es que la idea siempre me ha llamado la atención, pero siempre termino regresando a lo escrito por 2 razones:
- Si no tengo tiempo para escribir, mucho menos para editar video (ya ni se diga grabar)
- Me gusta más escribir que grabar
Pero no estoy peleado con la idea. El problema principal es que la vida de adulto me alcanzó, y desde el punto de vista de mi yo de 20 años, es horrible no tener el tiempo que tenía en ese entonces. Como siempre lo he dicho, no es un sacrificio, sino un intercambio de tiempo personal por tiempo con la familia, de unas experiencias por otras. Y la neta, me gusta ser papá. Pero dicho lo anterior, en algún momento haré el experimento y veré qué tanto me toma hacer un video de un escrito del blog.
También los puedo mencionar que, ahora que soy cinta negra en karate, quiero ayudar a difundir el estilo que practico (tradicional de Okinawa) en el ámbito internacional. Todavía no estoy seguro cómo, pero algo voy a hacer.
En ondas profesionales, ahora que hice contacto con la comunidad de investigadores de México, y siguiendo en contacto con gente de la Universidad de Guadalajara, estoy buscando la forma de hacer algo en conjunto. Ya veremos qué sale de esta idea.
Por lo demás, aquí sigo. El blog no lo abandono, y creo que nunca lo haré. Sigo leyendo TODOS los comentarios que me llegan, y sigo respondiendo correos cuando alguien me escribe.
Pasen todos una excelente noche de San Silvestre, y que el 2026 les traiga dicha, y sobre todo, lo que requieran para que sus planes se concreten y lleven a cabo. Reciban un fuerte abrazo desde Saitama, porque ya no vivo en Tokio, aunque me queda aquí en corto.
¡Adiós serpiente! Nos vemos en 12 años.
The post El 2025 en un kanji first appeared on ¡Un mexicano en Japón!.December 15, 2025
Gwolf
Unique security and privacy threats of large language models — a comprehensive survey
This post is a review for Computing Reviews for Unique security and privacy threats of large language models — a comprehensive survey , a article published in ACM Computing Surveys, Vol. 58, No. 4
Much has been written about large language models (LLMs) being a risk to user security and privacy, including the issue that, being trained with datasets whose provenance and licensing are not always clear, they can be tricked into producing bits of data that should not be divulgated. I took on reading this article as means to gain a better understanding of this area. The article completely fulfilled my expectations.
This is a review article, which is not a common format for me to follow: instead of digging deep into a given topic, including an experiment or some way of proofing the authors’ claims, a review article will contain a brief explanation and taxonomy of the issues at hand, and a large number of references covering the field. And, at 36 pages and 151 references, that’s exactly what we get.
The article is roughly split in two parts: The first three sections present the issue of security and privacy threats as seen by the authors, as well as the taxonomy within which the review will be performed, and sections 4 through 7 cover the different moments in the life cycle of a LLM model (at pre-training, during fine-tuning, when deploying systems that will interact with end-users, and when deploying LLM-based agents), detailing their relevant publications. For each of said moments, the authors first explore the nature of the relevant risks, then present relevant attacks, and finally close outlining countermeasures to said attacks.
The text is accompanied all throughout its development with tables, pipeline diagrams and attack examples that visually guide the reader. While the examples presented are sometimes a bit simplistic, they are a welcome guide and aid to follow the explanations; the explanations for each of the attack models are necessarily not very deep, and I was often left wondering I correctly understood a given topic, or wanting to dig deeper – but being this a review article, it is absolutely understandable.
The authors present an easy to read prose, and this article covers an important spot in understanding this large, important, and emerging area of LLM-related study.
December 05, 2025
Victor Martínez
Moodle 4.5 LTS
Este año me propuse en verano hacer el cambio de versión Moodle para pasarme a la versión de soporte a largo plazo (Long Term Support LTS) y medio lo preparé, fui al DC25, estuve haciendo otras cosas, salió Debian 13 (Trixie) y lo que pensé que era un montón de tiempo para realizar y probarlo antes de que regresáramos a clase, resultó en la realidad quedarme en apenas cuatro días incluyendo un fin de semana.
Preferí esperar al final de semestre… y pasó que los estudiantes de UPN se fueron a paro en los últimos días de octubre y a la fecha no hay solución.
En noviembre pensé en probar en mi máquina de desarrollo Trixie y Moodle para en la de producción eventualmente realizar el mismo proceso, en la práctica probé si se podía pasar a 4.5 desde 4.1 en PHP7.4 y más o menos quedó, pero resulta que el LTS actual solo soporta hasta 8.3 y Trixie incluye 8.4, volví a probar y efectivamente hay que mover algún pedacito de la revisión de ambiente con un hack medio feo, comentar en mi caso la revisión de la versión, recuerdo en 3.1 haber incluido la versión con un > más alto del que venía incluido, si más elegante pero que no documente tan a detalle para recuperar en esta ocasión y ahora que pase a producción espero poner en mi cheatsheet que supongo si puedo legarle a alguien esta tarea será más bien la documentación.
Total que en desarrollo ya esta funcionando y más o menos probado, por supuesto falta la prueba del usuario de a pie, pero esa prefiero hacerla en producción cuando haya acceso físico a las máquinas, fue muy interesante porque antes del paro estuvo fallando mucho la energía eléctrica un poco por eso y por el asunto de una falla en la actualización, que tiene rato que no me pasa, que no me he animado a actualizar.
Con algo de tiempo extra me dí cuenta que efectivamente tiene un rato que sigo el LTS con git y más bien hago mi repositorio local con 3.1 fue el último que jale directamente del git de Moodle y solo actualizaba con pull, a partir de ahí 3.5, 3.9, 4.1 y ahora 4.5.
A partir de 3.1 ya en git se termine con este esquema, primero por el firewall que me bloqueaba github, pero especialmente para poder mantener los temas, plugins, cursos y añadidos en un solo lugar actualizar las muchas instancias que en esa época me tocaba mantener, el día de hoy son sólo cuatro, una sola de producción, pero en su momento llegó a la veintena y hacerlo para 2 me toma el mismo tiempo que para más ya con el flujo bien trabajado, entonces se quedó así… he tenido curiosidad de como hace informática, que he visto más bien usan el stable con un ciclo de un año a diferencia de los 3 años de soporte del LTS y como tiene rato que no soy tutor en los cursos en línea de otros programas no estoy tan seguro, pero así hicieron con los sistemas en el confinamiento según para no saturar los servidores.
November 21, 2025
Victor Martínez
Soy Joven
Este texto lo escribo como hija, como hermana mayor, como estudiante de la Universidad Pedagógica 141 y, más que nada, como joven que vive, observa y cuestiona el mundo que le rodea. Lo escribo desde el lugar que ocupa una hermana mayor que aprende a ser ejemplo incluso cuando también tiene dudas y miedos; y desde el compromiso que implica formarme como futura docente y/o orientadora
Lo escribo en apoyo a mis compañeros de la Universidad Pedagógica Nacional, sede Ajusco, quienes en este momento se encuentran en paro, ejerciendo su derecho a manifestarse y a exigir condiciones dignas para su formación y para el futuro de la educación en nuestro país. Su lucha no es solo suya: es un reflejo de las problemáticas que atraviesan nuestros espacios educativos, de las carencias que se han normalizado y de la urgencia de una transformación real.
Lo escribo como un desahogo para mí, como joven estudiante que hoy elijo levantar la voz a mi manera no con gritos si no con lírica, no con violencia si no palabras este poema, inspirado en el histórico discurso del 2 de diciembre de 1972 de Salvador Allende, cuando afirmó con fuerza y convicción que “ser joven y no ser revolucionario es una contradicción hasta biológica” Este es un recordatorio de que la juventud es impulso, es mirada crítica, es inconformidad ante la injusticia y, sobre todo, es posibilidad de cambio.
Te invito querido lector que leas esto con ojos críticos, a actuar ante una injusticia, pues somos seres históricos, somos hijos de quienes lucharon para nosotros estar aquí y lucharemos para los que vienen atrás de nosotros, pues somos la revolución.
ATTM: V.V.
Universidad Pedagógica Nacional 141
Guadalajara, Jalisco.
November 19, 2025
Gwolf
While it is cold-ish season in the North hemisphere...
Last week, our university held a «Mega Vaccination Center». Things cannot be small or regular with my university, ever! According to the official information, during last week ≈31,000 people were given a total of ≈74,000 vaccine dosis against influenza, COVID-19, pneumococcal disease and measles (specific vaccines for each person selected according to an age profile).
I was a tiny blip in said numbers. One person, three shots. Took me three hours, but am quite happy to have been among the huge crowd.

(↑ photo credit: La Jornada, 2025.11.14)

And why am I bringing this up? Because I have long been involved in organizing DebConf, the best conference ever, naturally devoted to improving Debian GNU/Linux. And last year, our COVID reaction procedures ended up hurting people we care about. We, as organizers, are taking it seriously to shape a humane COVID handling policy that is, at the same time, responsible and respectful for people who are (reasonably!) afraid to catch the infection. No, COVID did not disappear in 2022, and its effects are not something we can turn a blind eye to.
Next year, DebConf will take place in Santa Fe, Argentina, in July. This means, it will be a Winter DebConf. And while you can catch COVID (or influenza, or just a bad cold) at any time of year, odds are a bit higher.
I know not every country still administers free COVID or influenza vaccines to anybody who requests them. And I know that any protection I might have got now will be quite weaker by July. But I feel it necessary to ask of everyone who can get it to get a shot. Most Northern Hemisphere countries will have a vaccination campaign (or at least, higher vaccine availability) before Winter.
If you plan to attend DebConf (hell… If you plan to attend any massive gathering of people travelling from all over the world to sit at a crowded auditorium) during the next year, please… Act responsibly. For yourself and for those surrounding you. Get vaccinated. It won’t absolutely save you from catching it, but it will reduce the probability. And if you do catch it, you will probably have a much milder version. And thus, you will spread it less during the first days until (and if!) you start developing symptoms.
November 14, 2025
Gwolf
404 not found
Found this grafitti on the wall behind my house today:

November 05, 2025
Victor Martínez
Mi contenido en youtube
No es muy popular… 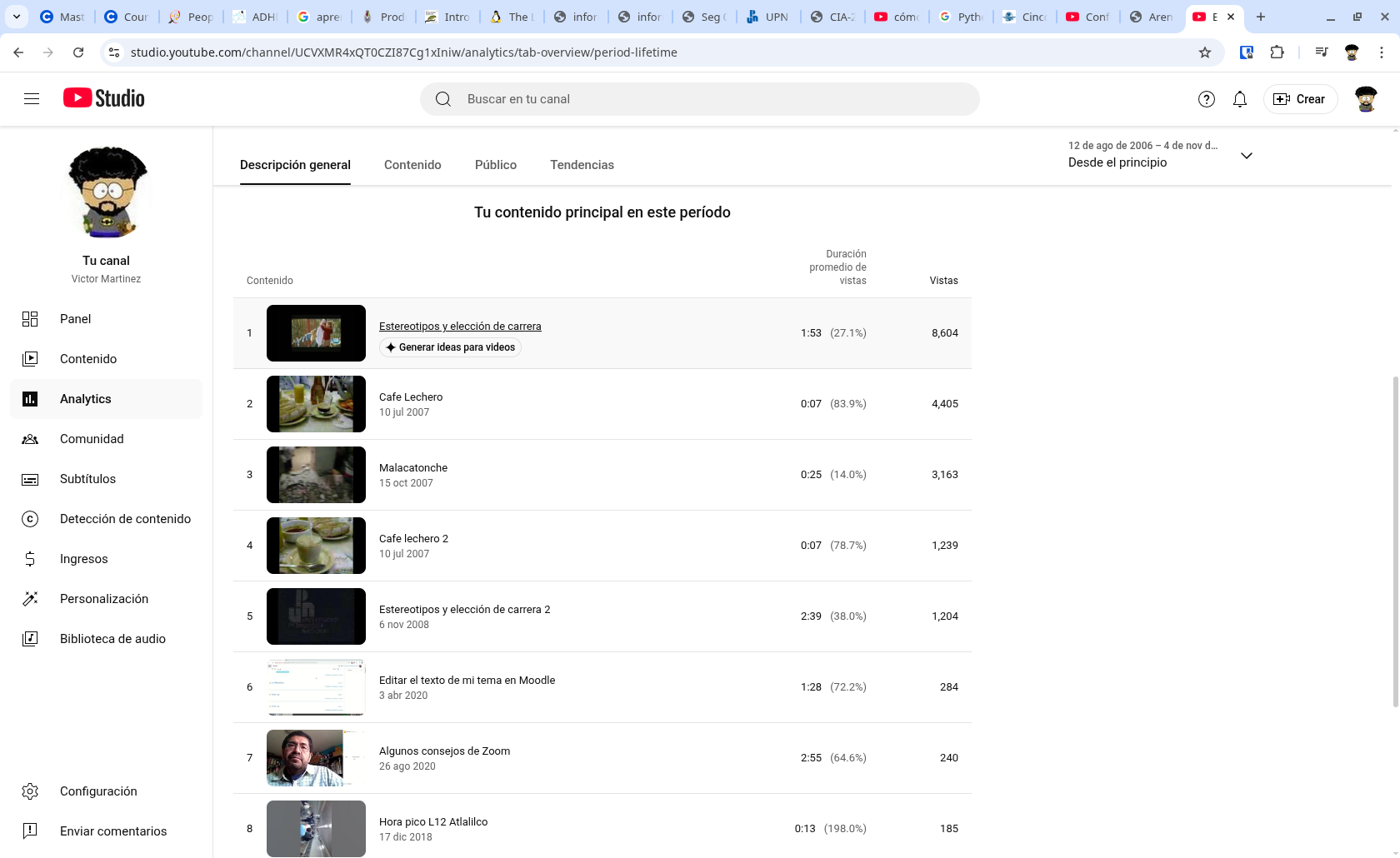
Pero mejor en texto
1 Estereotipos y elección de carrera 6 nov 2008 1:53 (27.1%) 8,604
2 Cafe Lechero 10 jul 2007 0:07 (83.9%) 4,405
3 Malacatonche 15 oct 2007 0:25 (14.0%) 3,163
4 Cafe lechero 2 10 jul 2007 0:07 (78.7%) 1,239
5 Estereotipos y elección de carrera 26 nov 2008 2:39 (38.0%) 1,204
6 Editar el texto de mi tema en Moodle 3 abr 2020 1:28 (72.2%) 284
7 Algunos consejos de Zoom 26 ago 2020 2:55 (64.6%) 240
8 Hora pico L12 Atlalilco 17 dic 2018 0:13 (198.0%) 185
9 Vista de lectura en Power Point 22 jun 2022 0:53 (34.7%) 159
10 Crear una cuenta en Moodle en sagan 2:27 (30.6%) 142
El 1 y 5 son un video que querian compartir unas estudiantes de psicología cuando era un poco latoso crear una cuenta en Youtube y para no hacerlo me pidieron que lo hiciera y que ademas por la época tuvo que ser en dos partes que también era difícil entonces dividir un video, ese es el contenido más popular de mi canal
2 es café lechero servido en el restaurante la parroquia hoy día los portales en el puerto de Veracruz tomado con mi camara Panasonic que en esa época 2007, no incluia microfono…
3 es de cuando se cayó el aplanado del cemento del techo de la cocina en octubre de 2007, por un mal trabajo del albañil, igual sin audio…
4 otro de la cuatro veces heroica… bueno del café…
6 un video que prepare durante el confinamiento como apoyo a mis estudiantes que terminó siendo un pequeño curso de Moodle para toda la comunidad UPN.
7 Durante el confinamiento con mis compañeros y las docentes de mis hijos vi que había un montón de dudas sobre Zoom, aquí grabe de manera breve y concisa los mejores consejos que saque de errores y consultas que había en esos días.
8 En 2018 como es el transbordo largo de Atlalilco originalmente para Fernando Barajas que le gustaron las caminadoras y tuvo la fortuna de usar ese transbordo cuando no había mucha gente.
9 Durante el encuentro ELCHAT de 2022 como no usamos Zoom, como usar Power Point en un modo distinto al de presentar para utilizarlo con programas diferentes, por supuesto esto desde entonces se puede lograr con un PDF y el navegador, pero en ese año para algunos aún era un poco nuevo.
10. De la plataforma en Moodle del Cuerpo Académico que tenemos corriendo desde 2007, como registrarse que desde 2024, no podemos usar cuentas de yahoo o gmail porque no nos han querido añadir SPF o DKIM, dicho sea de paso la presentación que usó de ejemplo para el video anterior Claroline la cual mantuvimos como hasta 2010, pero nos pasamos a Moodle por el abandono y eventual cambio de la misma a el tipo MOOC.
Son las estadísticas desde 12 de agosto de 2006 al 4 de noviembre de 2025, por eso digo que no son tan popular, a lo mejor haciendo un análisis por caso si fueron populares y útiles en su momento, pero no voy que vuele para youtuber o influencer…
Si gustan ver cada uno de ellos por acá esta mi canal
October 23, 2025
Victor Martínez
Lapsus, errata o algo nos querrán decir…
Por 2023, mencione que el Sistema Integrado de Información de la Educación Superior que publica información muy interesante instituciones de educación superior al respecto del logo.
Al día de hoy el SIIES [1] y desde que se lanzó no hay forma de contacto o mención de quien lo actualiza, es decir a quién dirigirse en caso de necesitarlo, desde entonces tiene información importante, pero hasta hoy todavía para la UPN viene el logo de la misma, pero de Colombia. En la entrada anterior mencioné que ya había intentado contactarlos para corregirlo, lo intente por redes a algún correo que no es precisamente del SIIES y con estas entradas y no parece interesarles.
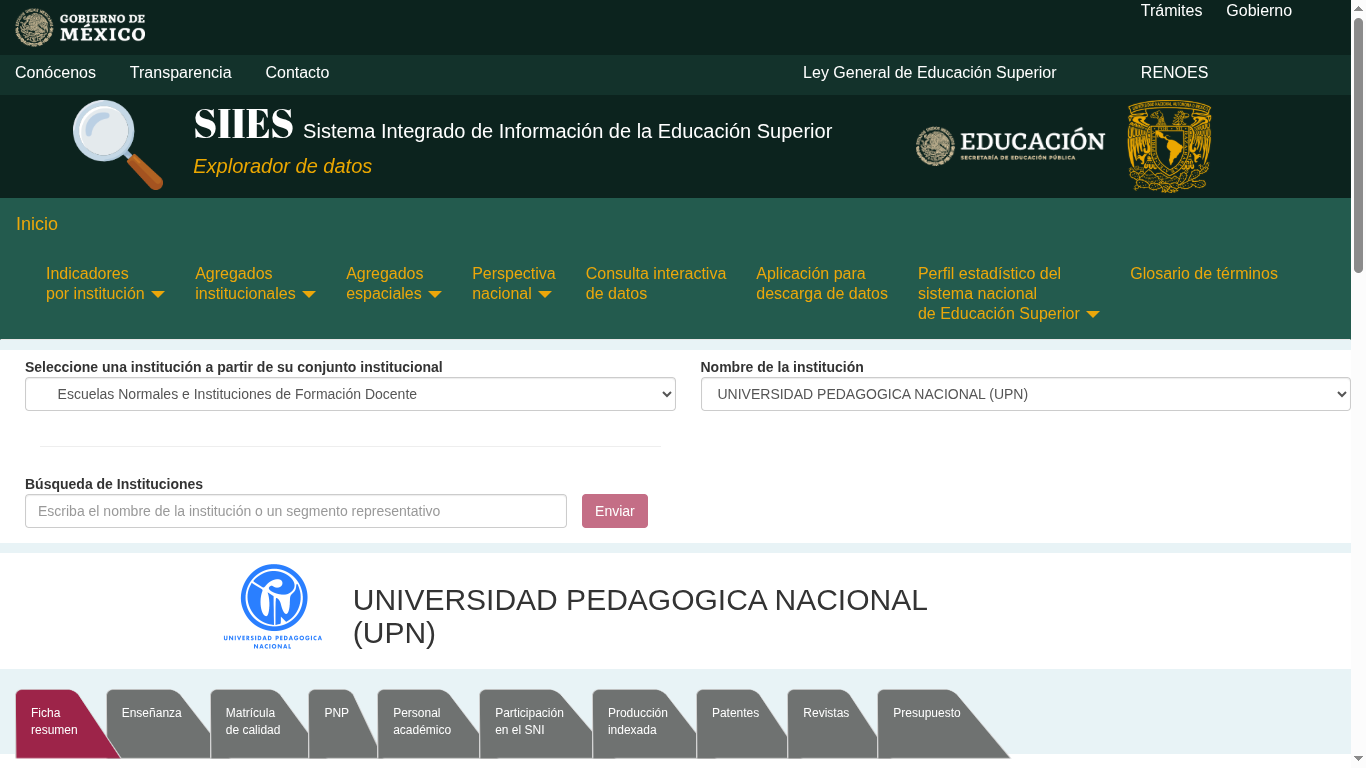
El logo de UPN, de Colombia…
Más interesante en lugar de aparecer como institución de educación pública, federal. Como si lo hacemos en otros documentos, aquí aparecemos en «Escuelas Normales e Instituciones de Formación Docente» que o es un lapsus o algo no están queriendo sugerir.
[1] https://www.siies.unam.mx/
October 21, 2025
Gwolf
LLM Hallucinations in Practical Code Generation — Phenomena, Mechanism, and Mitigation
This post is a review for Computing Reviews for LLM Hallucinations in Practical Code Generation — Phenomena, Mechanism, and Mitigation , a article published in Proceedings of the ACM on Software Engineering, Volume 2, Issue ISSTA
How good can large language models (LLMs) be at generating code? This may not seem like a very novel question, as several benchmarks (for example, HumanEval and MBPP, published in 2021) existed before LLMs burst into public view and started the current artificial intelligence (AI) “inflation.” However, as the paper’s authors point out, code generation is very seldom done as an isolated function, but instead must be deployed in a coherent fashion together with the rest of the project or repository it is meant to be integrated into. Today, several benchmarks (for example, CoderEval or EvoCodeBench) measure the functional correctness of LLM-generated code via test case pass rates.
This paper brings a new proposal to the table: comparing LLM-generated repository-level evaluated code by examining the hallucinations generated. The authors begin by running the Python code generation tasks proposed in the CoderEval benchmark against six code-generating LLMs. Next, they analyze the results and build a taxonomy to describe code-based LLM hallucinations, with three types of conflicts (task requirement, factual knowledge, and project context) as first-level categories and eight subcategories within them. The authors then compare the results of each of the LLMs per the main hallucination category. Finally, they try to find the root cause for the hallucinations.
The paper is structured very clearly, not only presenting the three research questions (RQ) but also referring to them as needed to explain why and how each partial result is interpreted. RQ1 (establishing a hallucination taxonomy) is the most thoroughly explored. While RQ2 (LLM comparison) is clear, it just presents straightforward results without much analysis. RQ3 (root cause discussion) is undoubtedly interesting, but I feel it to be much more speculative and not directly related to the analysis performed.
After tackling their research questions, Zhang et al. propose a possible mitigation to counter the effect of hallucinations: enhance the LLM with retrieval-augmented generation (RAG) so it better understands task requirements, factual knowledge, and project context. The presented results show that all of the models are clearly (though modestly) improved by the proposed RAG-based mitigation.
The paper is clearly written and easy to read. It should provide its target audience with interesting insights and discussions. I would have liked more details on their RAG implementation, but I suppose that’s for a follow-up work.
October 14, 2025
Gwolf
Can a server be just too stable?
One of my servers at work leads a very light life: it is our main backups server (so it has a I/O spike at night, with little CPU involvement) and has some minor services running (i.e. a couple of Tor relays and my personal email server — yes, I have the authorization for it 😉). It is a very stable machine… But today I was surprised:
As I am about to migrate it to Debian 13 (Trixie), naturally, I am set to reboot it. But before doing so:
$ w
12:21:54 up 1048 days, 0 min, 1 user, load average: 0.22, 0.17, 0.17
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
gwolf 192.168.10.3 12:21 0.00s 0.02s sshd-session: gwolf [priv]
Wow. Did I really last reboot this server on December 1 2022?
(Yes, I know this might speak bad of my security practices, as there are several kernel updates I never applied, even having installed the relevant packages. Still, it got me impressed 😉)
Debian. Rock solid.

September 22, 2025
Victor Martínez
Un par de erratas
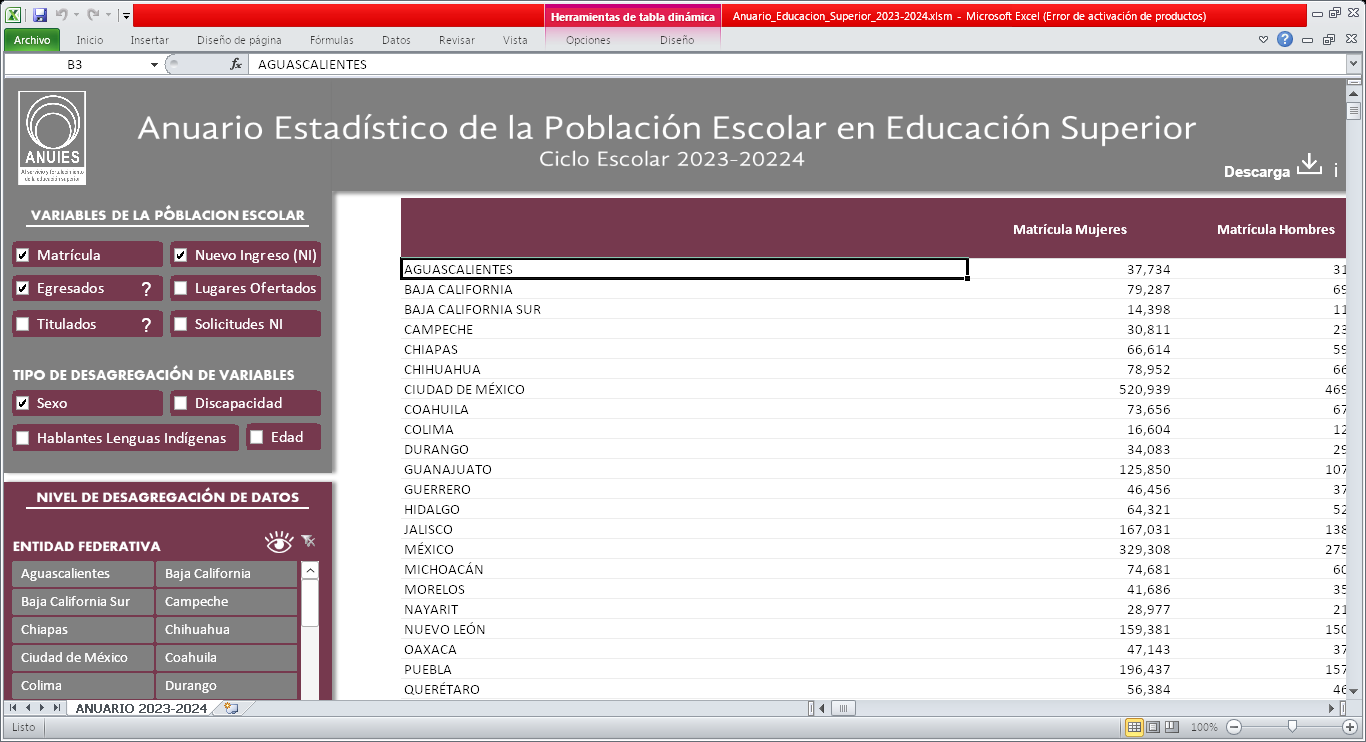
Recientemente, bueno una no tan recién, encontré dos errores uno, en los Anuarios Estadísticos de Educación Superior de ANUIES, especialmente en el de 2023-2024, en la cabecera está mal la fecha, que puede ser un error simple de dedo, lo reporte en abril de este año al correo que proveen en la página como contacto, en lugar de decir 2023-2024, dice 2023-20224.
De hecho fuí y descargue el archivo hoy, previendo que ya lo hubieran arreglado, no parece ser así [1]
Y el segundo y más interesante es del resumen de actividades de la Comisión Interna de Administración en su segunda sesión del año, la cual revisamos en clase para conocer la matrícula escolar en Ajusco y unidades de la Ciudad de México [2], nos encontramos con esto:
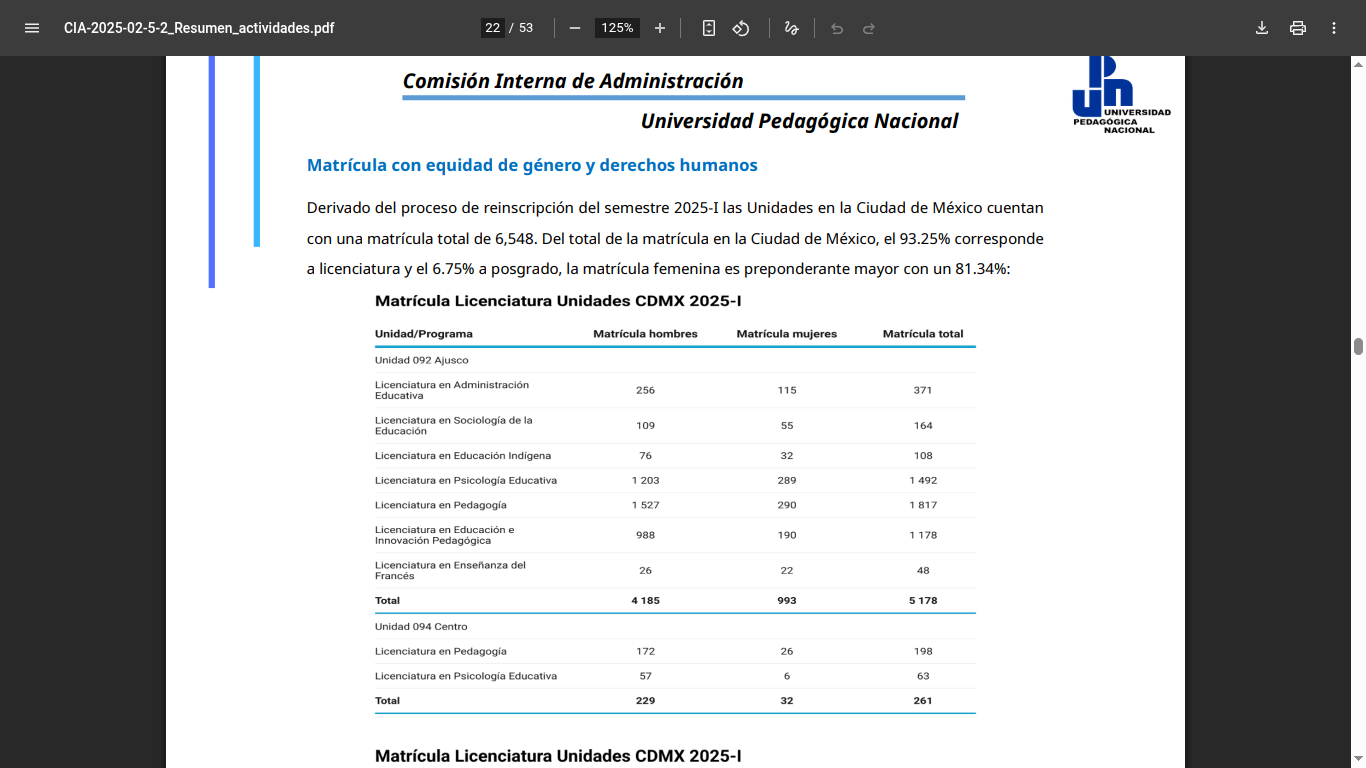
Que no es tanta sorpresa, dice que «la matrícula femenina es preponderantemente mayor con un 81.34%», lo cual es más o menos lo esperado y parte de un ejercicio que se realiza más adelante en el semestre al trabajar con hoja de cálculo y graficas, pero que adelantamos para mostrar la búsqueda en sitios de gobierno y la complejidad que presenta, pero el punto importante aquí es que si la afirmación entre comillas que se puede ver en la captura es correcta, entonces las etiquetas de datos están incorrectas, es decir matrícula hombres, matricula mujeres, o si las etiquetas son correctas la afirmación de arriba es incorrecta, por el comportamiento de la Unidad Ajusco y de la licenciatura lo más probable es que las etiquetas están incorrectas, por supuesto se puede cotejar con el anuario de ANUIES, pero no he hecho el ejercicio, puesto que ya está disponible el de 24-25.
[1] https://www.anuies.mx/gestor/data/personal/anuies05/anuario/Anuario_Educacion_Superior_2023-2024.zip
[2] https://cia.upnvirtual.edu.mx/docs/022025/CIA-2025-02-5-2_Resumen_actividades.pdf
I pay for
32 cores, and gona use all of them…
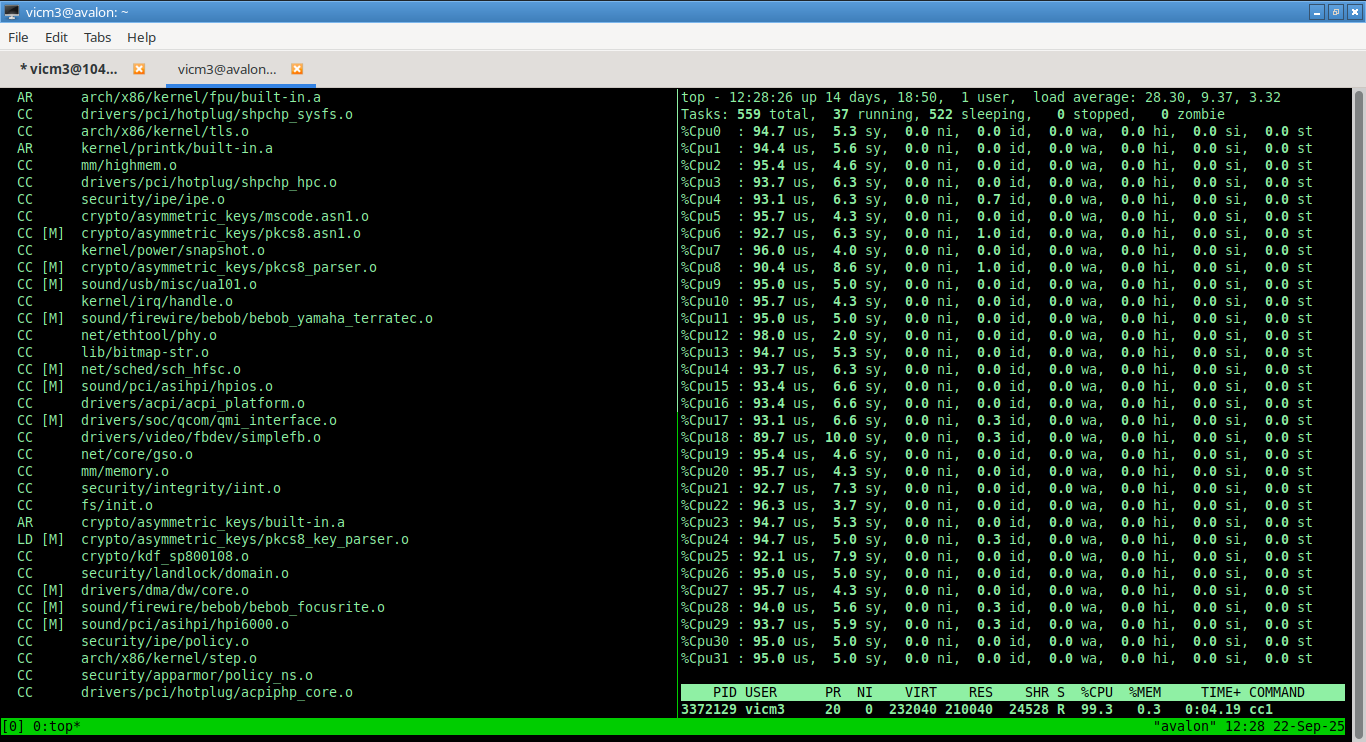
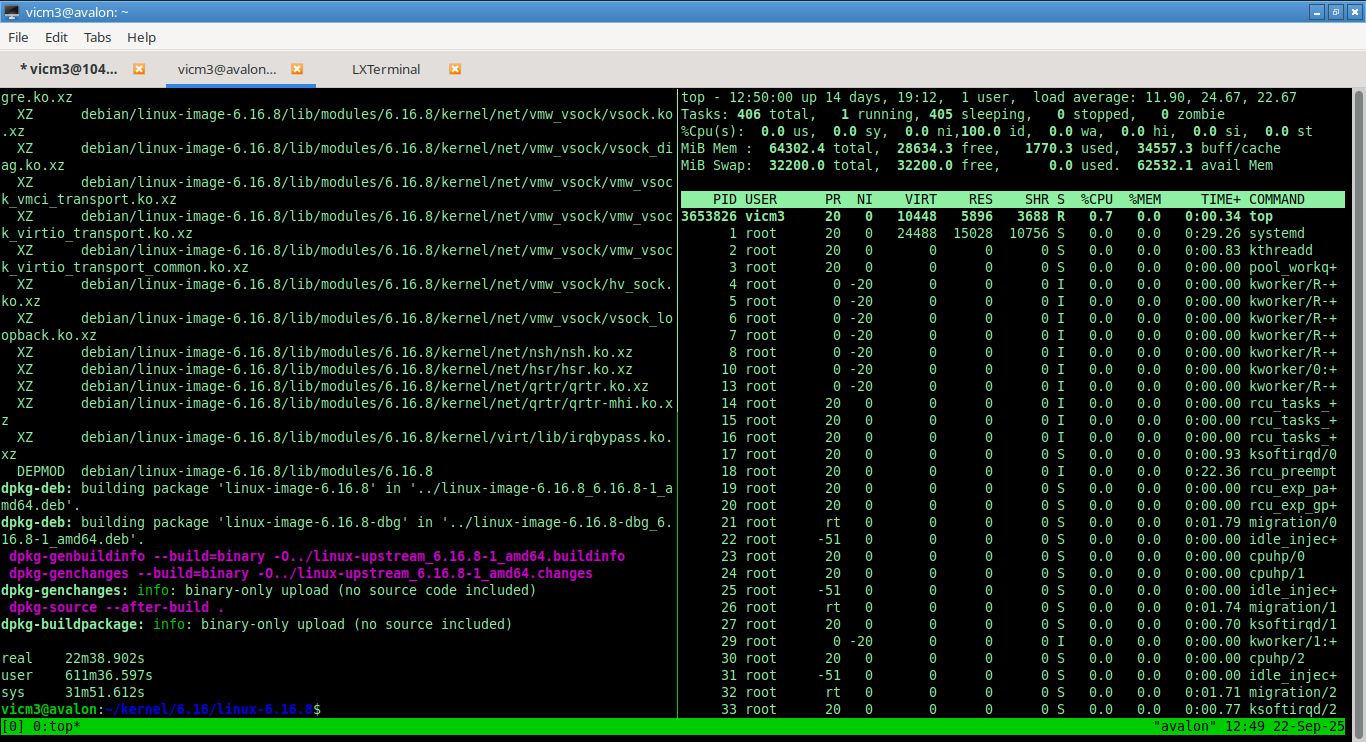
Or if you are on a CLI browser
11:40:03 AM CPU %user %nice %system %iowait %steal %idle 12:20:01 PM all 0.01 0.00 0.01 0.01 0.00 99.97 12:30:03 PM all 28.12 0.00 1.86 0.11 0.00 69.91 12:40:03 PM all 94.25 0.00 5.50 0.00 0.00 0.24 12:50:01 PM all 68.60 0.00 3.51 2.67 0.00 25.23
11:40:03 AM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked 12:20:01 PM 0 468 0.00 0.00 0.00 0 12:30:03 PM 35 618 34.77 16.78 6.56 0 12:40:03 PM 35 616 33.82 32.07 19.98 0 12:50:01 PM 0 472 10.95 24.26 22.55 0 time real 22m38.902s user 611m36.597s sys 31m51.612s